The ASCII character encoding
may now be somewhat obsolete,
but its influences on computing
still show.
There are also
interesting things to learn
about how it was designed.
All of this, of course,
is not at all new.
ASCII is now over fifty years old,
but I had never before given it much thought.
When I actually looked into it,
I was pleasantly surprised.
The ASCIIbet
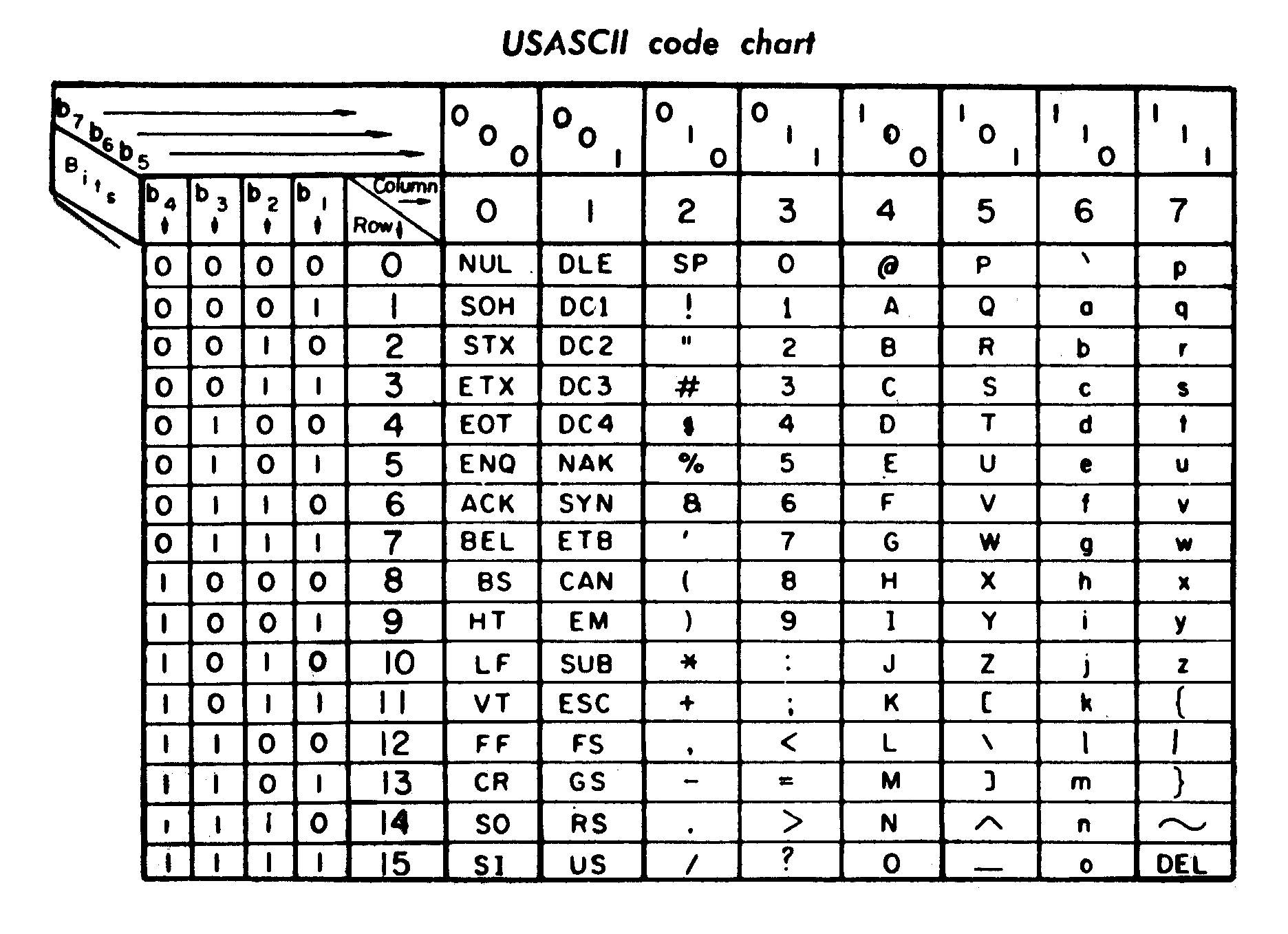
This is a classic ASCII code chart,
which is laid out in a way
that shows many of its design niceties.
An obvious property
is the overall ordering of the characters.
The characters are laid out such that
common separators appear first,
e.g. space, hyphen, full stop and slash,
followed by numbers,
capital letters,
and finally minuscule letters.
This layout means that
ASCII strings can easily be sorted
by comparing their numerical values.
The resulting order is called ASCIIbetical.
Hurray for lazy programmers!
ASCII for humans
The layout of the chart also reveals
how human-readable ASCII can be.
By looking at the first
two or three most significant bits,
many of the characters become obvious.
-
Values starting with 011
represent the digit character
corresponding to the last four bits.
For example, 0110011 is the character “3”.
-
Values starting with 010
sometimes represent
the shifted symbol corresponding to the digit.
This was based on the layouts of electric typewriters at the time,
so doesn’t hold up as much today.
It is still accurate for 1, 3, 4 and 5 on US QWERTY layouts.
For example, 0100011 is the character “#”.
-
Values starting with 10
represent the capital letter at
the position in the alphabet of the last 5 bits.
For example, 1000011 is the character “C”.
-
Similarly, values starting with 11
represent the minuscule letter at
that position in the alphabet.
For example, 1100011 is the character “c”.
There are also other aligned shifted characters,
such as ,./ and <>?,
which have their third most significant bit flipped.
The characters []| also correspond to {}|
with their second most significant bit flipped.
Delete
This human-readability would have been
much more useful than it is now
back when ASCII text was often stored on punched paper tape.
Paper tape is also the reason
there is one control-code
that doesn’t appear in the first 32 positions
with the rest.
At position 127,
the DEL is represented in binary as 1111111.
On paper tape,
this means that any previously punched character
can be replaced with DEL by punching the remaining holes.
This clever bit of design means that
characters can be “erased” even when represented physically.
Diacritics
Although this clever design is no longer relevant,
there are some less clever decisions that have had
a lot of influence.
The caret, backtick, and tilde characters
were included in ASCII as
a sort of work-around,
intended to be used as diacritics
rather than including accented letters themselves.
But even though we now have proper accented characters
thanks to Unicode,
the ASCII diacritics are still commonly used in programming,
and are still standard on keyboard layouts.
I sometimes wonder if a non-programmer
has ever purposely typed a backtick.
Caret notation
By far the most interesting thing
I discovered when reading about ASCII
was the origin of caret notation
and many common terminal key sequences.
For example, the control-C sequence, or ^C.
On old systems,
the control key was used literally to enter control-codes.
The way this worked was
that each character in the 100 and 101 columns
(the capital letters and some punctuation),
corresponded to a control-code in the 000 and 001 columns.
These sequences were represented with caret notation,
so ^@ was NUL, ^A was SOH, and so on.
DEL 1111111 was represented by ^?,
where ? is 0111111.
This means that the control-code
for a key could be calculated by
inverting the most significant bit.
Most of the ASCII control-codes are no longer relevant,
but some of the key sequences
are still very common in the terminal.
The most common of these is,
of course, ^C,
used to interrupt program execution.
The corresponding control-code is ETX,
end of text.
Similarly, ^D,
which indicates end-of-file,
corresponds to EOT, end of transmission, in ASCII.
Another somewhat common sequence is ^Z
for suspending processes.
This comes from the control-code SUB, substitute.
Many terminals still clear the screen on ^L,
which corresponds to FF, form feed.
This originally caused printers to load the next page.
Probably less well known
are the sequences ^S and ^Q,
which can be used to pause and resume output.
In ASCII, these were simply DC3 and DC1,
two of the four device-specific control-codes.
The Teletype Model 33 implemented these
as XOFF and XON,
which turned the tape reader off and on.
This definition stuck around.
That’s all
Those are basically what I found
to be the interesting parts of
the good old 7-bit character encoding
from a modern perspective.
It might not be useful information day-to-day,
but it hopefully makes for fun trivia.